
作业1
一
c++示例
|
1预处理
主要涉及到:1.头文件展开,基本上就是copy,头文件中包含了外部函数的声明,和一些结构体的定义。
2.宏替换(copy)
sh:
cpp ex.c -o example.i |
处理结果
/*头文件部分 |
2词法分析
主要是用于token流的生成,为了后续的ast的实现
[StartOfLine] 和 **[LeadingSpace]**:
- 这些标签表示该 token 是否位于行首,或者其前面是否有空格。
Loc:
- 表示 token 的来源文件和具体的行、列位置,帮助追踪每个 token 在源文件中的位置,方便调试或分析。
Spelling:
Spelling=<built-in>表示该 token 是来自于编译器的内置定义,而不是用户代码中的内容。例如,size_t、__builtin_va_list都是标准库或内置类型。
//clang -Xclang -dump-tokens -fsyntax-only ex.c > mytoken 2>&1 |
3语法分析(AST生成)
忽略了头文件的ast部分,可以看出主函数由几个声明组成,TranslationUnitDecl作为树根。
clang -E -Xclang -ast-dump ex.c > myparse 2>&1
TranslationUnitDecl 0xa5e388 <<invalid sloc>> <invalid sloc> |
4中间代码生成
ir是后端的开始,可以进行代码的优化,最终生成最终的汇编代码。
有了ir,那么为每一种os设计语言就不用考虑后端了,就直接涉及前端即可,只要能生成一样的ir格式。
无优化
clang -S -emit-llvm -fno-discard-value-names ex.c -o ex.ll -O0 -g0
格式和汇编差不多,但是寄存器数量是不受限制的,采用三地址码的格式,但是同一条指令相同寄存器,不能又做源又做汇编。
其中一开始是全局变量的定义,之后分别是函数声明和定义,文件最开头是架构信息为可选项,文件末尾则是一些个函数属性,函数利用#0,#1来选择是哪一个
; ModuleID = 'ex.c' |
O1优化
可以看出代码少了很多,主要优化部分在main以及print函数,优化点在参数的存储那一部分,无优化的时候每次调用函数的时候都会把参数存放在寄存器中
; ModuleID = 'ex.c' |
O2优化
感觉已经和O1没什么区别了,应该优化到尽头了
; ModuleID = 'ex.c' |
5汇编代码生成
无优化
非常正常的汇编代码,其中定义了每个section,其符合pic的规范,生成的目标文件需要经过got表的重定位(主要涉及到printf函数
callq printf@PLT)。PLT会经过got表的重定位,来装载符号地址。
.text |
O2优化
O1和O2的ir是差不多的,因此这里只显示了其中之一
其中的.标号则是为了pic定位设置的,访问全局变量,访问标号偏移的行对地址,再在相应的地方(got表)进行重定位。
.text |
6 可执行文件生成
这里细分可以分为两个步骤,一个是可重定位文件的生成,然后是可执行文件的生成,后者则需要链接器的参与。
前者只是扫描本汇编文件,生成符号表,但是外部符号,也就是定义在其他模块的符号,编译器并不认识,因此需要链接操作。
而链接又分为动态链接,以及静态链接,所谓pic就是相对于动态链接而言的(一个库代码copy处处运行,但是每个程序的虚拟地址映射都是不同的,因此需要运行时装载,应该是一个dlresolve来完成,记不清了),静态链接会一股脑的把目标文件和库文件有用的没用的放到一起,但是动态链接则是用哪个拿那个,因此需要重定位,运行时解析(plt的懒加载),但是一般都是在程序开始时加载got表。(这块很复杂,也不是一两句说的清的)。以下可以看出重定位文件和可执行文件的关系,静态链接没什么可说的,就拿动态链接举例了。
可以观察section表,注意和可执行文件的差异,可以看出可执行文件多了plt和got表
gcc -c ex.S -o ex.o |
二 IR编程
示例程序
main() { |
相应ir代码
SH:
llc -relocation-model=pic 2.ll -o main.S
gcc main.S -o two
; 模块ID = 'fib.ll' |
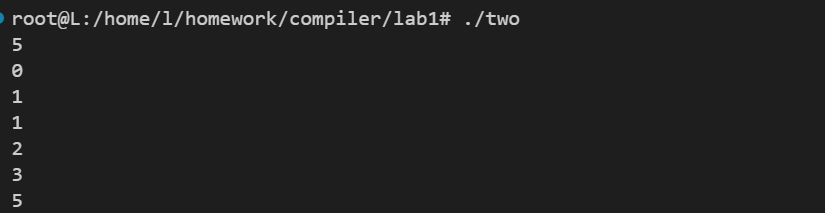
输出示例:
三 汇编编程
SH:
riscv64-unknown-linux-gnu-gcc -o three three.S -static
qemu-riscv64 ./three
|
结果:
因为没有exit系统调用,因此会直接段错误,但是不影响程序功能。
