
linux5.15之物理内存管理
比赛被内核和iot爆了,感觉逻辑并不复杂,但是没有网络就是做不出来,哎,从现在开始深入学习内核了,以5.15为例(gpt推荐的),浅显研究一下内核的一些模块。先研究内存管理。比赛之前分析过2.6.10的代码,但是还是太老了,好多特性都没有,就当个开胃前菜吧。本章学习linux内核物理内存架构(对各个架构的抽象)
参考
linux 5.15源代码。
https://docs.kernel.org/mm/physical_memory.html
http://www.wowotech.net/memory_management/426.html
内存管理
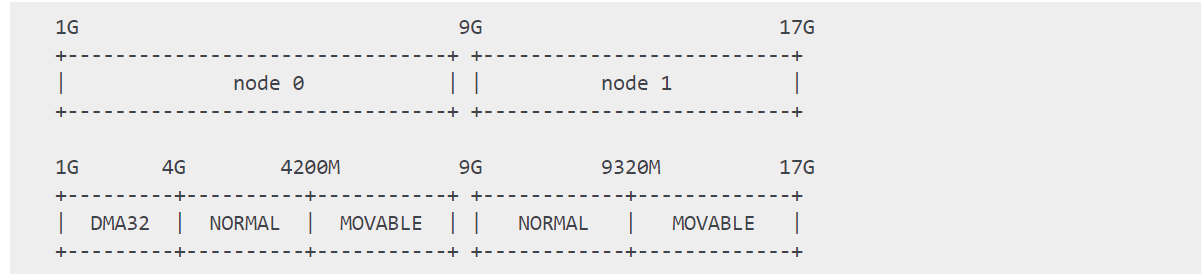
关于numa,node
这种和架构紧密相关的模块,都定义在arch下,并在相应的include中提供相应的接口,因此理解其接口功能即可。
在pc端,uma更加常见,但是为了统一的实现,uma可以看成一个简化版的numa。
内存管理中的第一个核心概念是非一致性内存访问(NUMA)。在多核和多插槽的机器中,内存可能被安排成不同的内存块(称为内存节点),访问这些内存节点的成本因与处理器的“距离”不同而有所差异。例如,每个 CPU 可能分配一个独立的内存块,或者在外围设备附近有一个适合 DMA(直接内存访问)的内存块。
每个内存块(bank)称为一个节点(node),在 Linux 中使用 struct pglist_data 来表示该概念,即使架构是 UMA(统一内存访问)。该结构总是通过其 typedef pg_data_t 来引用。可以使用宏 NODE_DATA(nid) 来引用某个节点的 pg_data_t 结构,其中 nid 是该节点的 ID。
对于 NUMA 架构,节点结构由架构特定的代码在启动过程中早期分配。这些结构通常会被分配到它们代表的内存块上。对于 UMA 架构,只使用一个静态的 pg_data_t 结构,称为 contig_page_data。关于节点的详细讨论会在“节点”章节中进一步说明。
关于zone
It is important to note that many kernel operations can only take place using
ZONE_NORMALso it is the most performance critical zone. Zones are discussed further in Section Zones.
整个物理地址空间被划分为一个或多个称为“zones”(区域)的块,这些区域代表内存中的某些范围。这些范围通常由访问物理内存的架构约束决定。 The memory range within a node that corresponds to a particular zone is described by a struct zone,并使用 zone_t 作为别名。每个 zone 都属于以下描述的类型之一。
ZONE_DMA 和 ZONE_DMA32 历史上代表适用于 DMA(直接内存访问)的内存区域,这些区域是为那些无法访问全部地址空间的外设设备准备的。尽管近年来有了更好的接口来获取具有特定 DMA 要求的内存(如使用通用设备的动态 DMA 映射),但 ZONE_DMA 和 ZONE_DMA32 仍然表示对访问有某些限制的内存范围。根据不同的架构,这些区域类型之一或两者都可以在编译时通过 CONFIG_ZONE_DMA 和 CONFIG_ZONE_DMA32 配置选项禁用。一些 64 位平台可能需要同时启用这两个区域,因为它们支持具有不同 DMA 地址限制的外设设备。
ZONE_NORMAL:是用于系统正常运行的内存区域,内核可以随时访问该区域中的内存。如果 DMA 设备能够访问所有可寻址的内存,则可以在此区域的页面上执行 DMA 操作。ZONE_NORMAL 始终是启用的。
ZONE_HIGHMEM: 是物理内存的一部分,但这部分内存不会永久映射在内核的页表中。内核只能通过临时映射来访问此区域中的内存。这个区域仅在某些 32 位架构上可用,并且通过 CONFIG_HIGHMEM 配置选项启用。
ZONE_MOVABLE:中的大多数页面内容是可以移动的。这意味着,尽管这些页面的虚拟地址保持不变,但它们的物理位置可以改变。ZONE_MOVABLE 常在内存热插拔时被使用,但也可以通过内核启动参数 kernelcore、movablecore 和 movable_node 在启动时进行配置。
ZONE_DEVICE:代表存在于设备上的内存区域,例如持久内存(PMEM)和 GPU 内存。它与传统的 RAM 区域类型具有不同的特性,存在的目的是为设备驱动程序识别的物理地址范围提供 struct page 和内存映射服务。
上述配置可以手控(通过一些配置选项),如下:

node结构体详解
其中包括了回收机制,和统计机制,以及一些个function字段。一些function字段:
- node_zones:
- 该节点的所有内存区域(zones),包括
ZONE_DMA、ZONE_NORMAL等。并不是每个 zone 都会被使用,但这是完整的 zone 列表。这个字段不仅在该节点的node_zonelists中引用,还可能在其他节点的node_zonelists中引用。- node_zonelists:
- 包含所有节点中所有 zones 的列表。该列表定义了在内存分配时优先选择的 zone 顺序。它由内核初始化时的
build_zonelists()函数设置。- nr_zones:
- 当前节点中被填充(populated)的 zones 数量。
- node_mem_map:
- 对于使用
FLATMEM内存模型的 UMA 系统,节点 0 的node_mem_map是一个struct pages数组,表示每个物理帧(page frame)。- node_page_ext:
- 对于使用
FLATMEM内存模型的 UMA 系统,节点 0 的node_page_ext是struct pages的扩展数组。仅在编译时启用了CONFIG_PAGE_EXTENSION时可用。- node_start_pfn:
- 该节点中的第一个页面帧编号(page frame number, PFN)。
- node_present_pages:
- 该节点中的物理页面总数。
- node_spanned_pages:
- 该节点所跨越的物理页面总数,包括可能的空洞(holes)。
- node_size_lock:
- 用于保护定义节点范围的字段的锁。仅在启用了
CONFIG_MEMORY_HOTPLUG或CONFIG_DEFERRED_STRUCT_PAGE_INIT配置选项时定义。可以使用pgdat_resize_lock()和pgdat_resize_unlock()操作node_size_lock。- node_id:
- 该节点的 ID(Node ID, NID),从 0 开始编号。
- totalreserve_pages:
- 该节点为用户态分配保留的页面数。
- first_deferred_pfn:
- 如果在大型机器上延迟了内存初始化,这是需要初始化的第一个页面帧编号(PFN)。仅在启用了
CONFIG_DEFERRED_STRUCT_PAGE_INIT时定义。
- deferred_split_queue:
- 按节点存储的延迟拆分的巨型页队列。仅在启用了
CONFIG_TRANSPARENT_HUGEPAGE时定义。
- __lruvec:
- 每个节点的
lruvec,用于存储 LRU(最近最少使用)列表及相关参数。仅在禁用内存控制组(memory cgroups)时使用,不应直接访问,应该通过mem_cgroup_lruvec()来获取lruvec。
/* |
node 结构体管理(stat)
位图中的每一位代表一个节点,stat是个数组,每个元素代表不同状态的节点数量。
|
内存分配
目前只知道两个,一种伙伴算法,一种slab分配器的小内存分配。
基本上所有的物理内存分配完都会进行mmu映射,不会直接使用物理内存,但是内存管理的时候是使用物理内存的,slab会保存物理地址与虚拟地址之间的映射,分配时会分配虚拟地址。
接下来学习slab分配器
以一些关键函数的实现过程为主线:
1. create_cache
涉及数据结构(根据所用分配器的不同而不同)
struct kmem_cache;//分配的cache |
函数调用链:
create_cache->kmem_cache_zalloc,__kmem_cache_create
kmem_cache_zalloc->kmem_cache_alloc->slab_alloc->__do_cache_alloc->__do_cache_alloc->__do_cache_alloc
kmem_cache_zalloc主要用来为cache分配相应的slab,和可分配内存,也可以分配cache的结构体,通过全局的缓存池。
__kmem_cache_create主要用来建立SLAB缓存池,管理cache。