
内存管理
为了研究内核的堆利用,因此需要学习一下内核的内存分配的相关知识
参考链接
https://github.com/andylhqiu/linux-2.6.10
https://s3.shizhz.me/linux-mm/3.2-wu-li-nei-cun/3.2.5-slab-slub-slob#org8b92d2a
https://elixir.bootlin.com/linux/v2.6.10/source/include/asm-ia64/mmzone.h
1.Page Frame Management
1.1 page frame
页描述符,通过lru将page连接起来。
/*/include/linux/mm.h*/ |
1.2 ARRAY
管理所有的页帧。
|
1.3 The Buddy System Algorithm
设计指南:
作为一种分配连续页帧的算法,需要应对外部碎片,两种解决方法:
1.利用虚拟地址映射,将连续的虚拟地址映射到不连续的页帧之上
2.算法本身的高效。(最好使用此方法因为有的操作是忽略mmu映射的(如:DMA))
但是不能频繁更改页表,因为会使缓冲区频繁刷新(更长的访存时间)。
算法描述:
Linux 采用的解决外部碎片问题的技术基于著名的伙伴系统算法。所有空闲的页面框架被分成10个不同大小的块列表,分别包含 1、2、4、8、16、32、64、128、256 和 512 个连续页面框架的块。每个块中第一个页面框架的物理地址是组大小的倍数:例如,一个包含 16 个页面框架的块的初始地址是 16 × 2^12 的倍数。
算法功能示例:
假设需要分配128个连续页帧,算法会一个一个查找,若有同样大小的,则分配,否则找更大的然后拆分,若最大的没有,那么会报错。
页帧合并条件:1.尺寸一样。2.连续。3.地址对齐
1.3.1 数据结构
linux中实现了连个不同的伙伴系统,一个处理DMA的页帧分配,另一个处理其余的。本节将学习伙伴算法依赖的数据结构
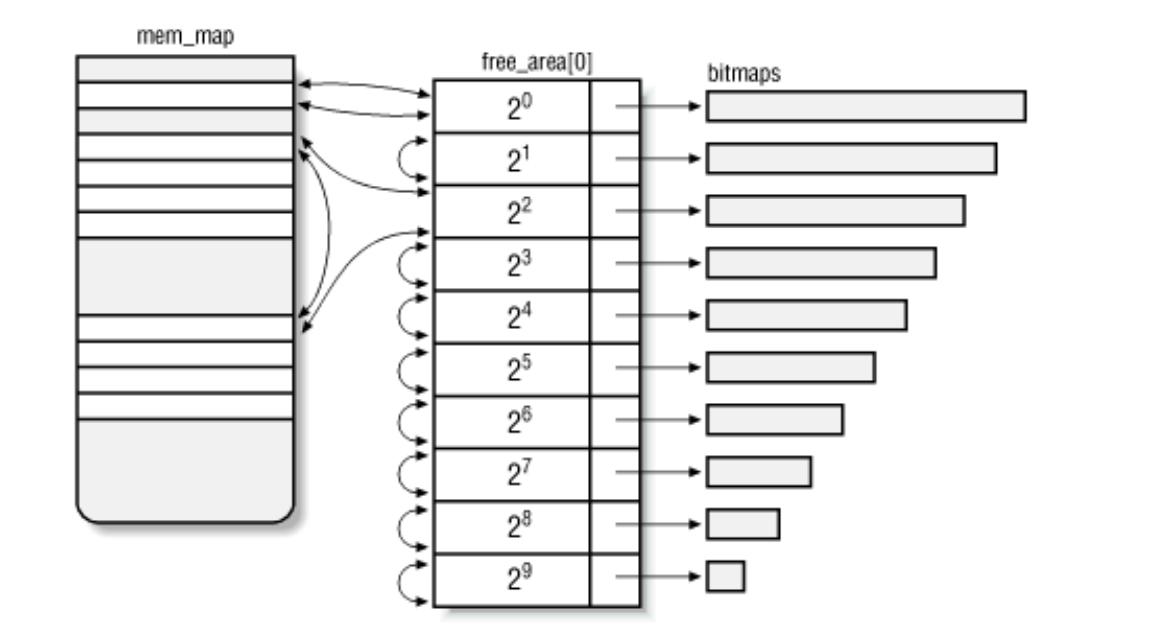
mem_map数组:这是前面介绍的结构。包含 10 个
free_area_struct类型元素的数组,每个组大小都有一个元素。free_area[0]指向由伙伴系统管理的页框数组,这些页框不适合 ISA DMA 操作,而free_area[1]指向适合 ISA DMA 的页框数组。十个二进制位图数组,每个组大小一个位图。每个伙伴系统都有自己的一组位图,通过这些位图来跟踪块是否被分配。
每个free_area[0] and free_area[1] 指向的数组的元素都是free_area_struct类型的。
2.6.10中结构体不太一样,定义在:/include/linux/mmzone.h文件中,每一个上述图片代表一个zone,
free_area[0]等演变成个不同的zone。
ZONE
|
free_area
第一次看有点奇怪,这链表怎么只存储指针,那么该如何定位数据?
其定位数据是通过一个宏,可以获得一个结构体中的其他元素,那么链表的操作就只用操作节点了,非常高效。
struct free_area { |
1.3.2 算法实现
在理解了一些数据结构基础之后,可以学习一下算法。
集中在
mm/page_alloc.c文件中
2.Page Frame Management
此部分学习小内存分配,会有外部碎片的问题,即将学习Linux的分配模式。
linux2.0采用几何分布分配的方法,也就是只能分配2的次幂大小的块,这就把内部碎片降低到了百分之50以内。
伙伴算法并不能支持上述要求,因此提出一种新算法(源自: slab allocator)
2.1设计准则
先学习以下基本的设计理念。
slab allocator算法基于以下几个准则设置的
存储的数据类型可能会影响内存区域的分配方式:例如,当内核为用户模式进程分配一个页面框架(page frame)时,内核会调用
get_free_page()函数,该函数会将页面填充为全零,以确保新分配的内存没有残留数据。slab 分配器的概念扩展了这一思想:它将内存区域视为对象,而这些对象不仅仅是简单的内存块,它们还包含一组数据结构和几个函数或方法,这些函数分别称为**构造函数(constructor)**和**析构函数(destructor)**。构造函数负责在内存分配时初始化该内存区域,而析构函数则负责在内存释放时对该内存区域进行清理。
slab 分配器确实在分配之后不会自动清除数据,而是将已经分配但释放的对象缓存起来,以便在下次需要同类对象时可以快速重复使用,避免频繁的内存分配和释放操作。这确实意味着,当某个对象从 slab 缓存中被重新分配时,它仍然可能包含上次使用时的旧数据。这种行为是有意为之的,以提高系统性能,减少不必要的初始化开销。
实际上,Linux 处理的内存区域不需要初始化或取消初始化。出于效率原因,Linux 并不依赖需要构造函数或析构函数的方法;引入 slab 分配器的主要动机是为了减少对伙伴系统分配器的调用。因此,尽管内核完全支持构造函数和析构函数的方法,但这些方法的指针通常都是
NULL。内核倾向于请求相同类型的区域
内存区域的请求可以根据其频率进行分类。对于某些特定大小且预期会频繁出现的请求,最有效的处理方式是创建一组具有合适大小的特殊用途对象,从而避免内部碎片化。与此同时,那些不常遇到的大小可以通过基于一系列几何分布大小的分配方案来处理(例如 Linux 2.0 中使用的 2 的幂次方大小),即使这种方法可能会导致内部碎片化。
数据结构的初始地址不容易集中在2的幂的分布上。
硬件缓存性能为尽可能减少对伙伴系统分配器调用提供了额外的理由:每次调用伙伴系统函数都会“弄脏”硬件缓存,从而增加平均内存访问时间。
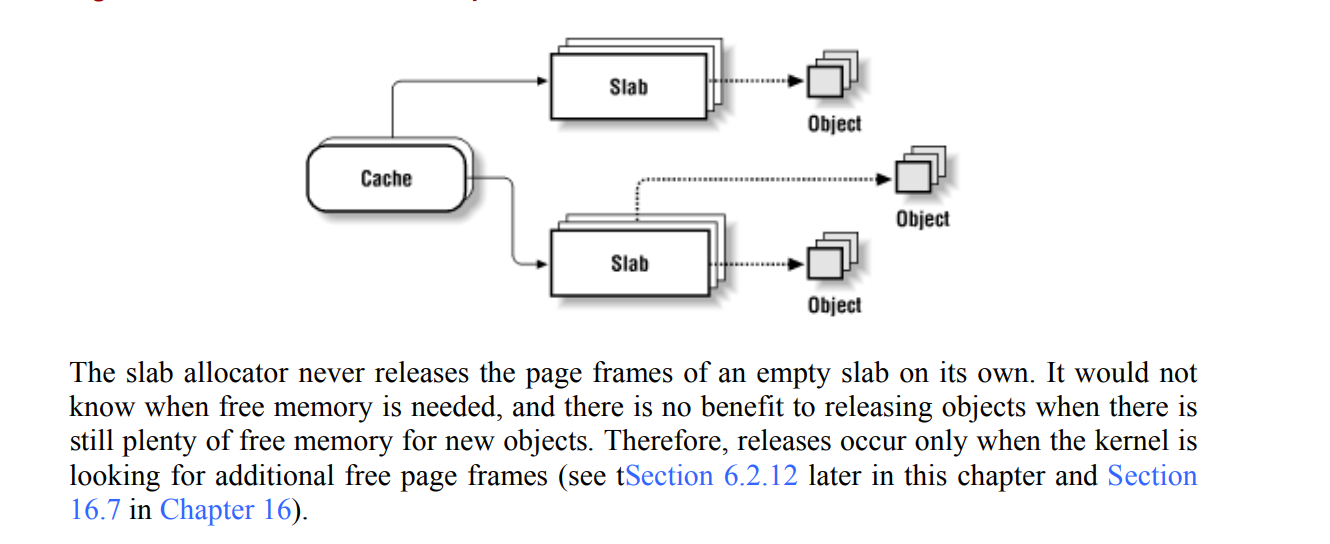
组件图解:
Cache:表示对象缓存(object cache),它存储了用于特定类型对象的 slab。Cache 负责管理 slab 并根据需要分配和回收对象。
Slab:Slab 是分配的基本单位,它由若干个已经初始化的对象组成。每个 slab 都包含多个对象的内存块,这些对象可以被分配给程序使用。
Object:具体的对象实例存储在 slab 中,当系统请求分配对象时,分配器从 slab 中取出空闲的对象返回给程序。当对象被释放时,它会返回到 slab 中,以供以后再次使用。
注:slab不会主动释放对象。
2.2数据结构
2.2.1 OVERLOOK
linux2.6.10为例
先理清不同数据结构之间的关系,slab.c中,一段注释描述的非常好。
内存被组织成缓存区,每种对象类型都有一个缓存区。
- 例如:
inode_cache、dentry_cache、buffer_head、vm_area_struct。- 每个缓存区由多个 slab 组成(它们很小,通常只占用一页内存,并且始终是连续的),每个 slab 包含多个已初始化的对象。
这意味着,构造函数只会在新分配的 slab 上使用,并且你必须将具有相同初始化的对象传递给
kmem_cache_free函数。每个缓存区只能支持一种内存类型(如
GFP_DMA、GFP_HIGHMEM、普通内存)。如果需要特殊的内存类型,则必须为该内存类型创建一个新的缓存区。为了减少内存碎片,slab 被分成三类:
- 已满的 slab(没有空闲对象)
- 部分使用的 slab
- 空的 slab(没有分配的对象)
如果存在部分使用的 slab,则新的分配会从这些 slab 中获取,否则从空的 slab 中分配,或是分配新的 slab。
* The memory is organized in caches, one cache for each object type. |
2.2.2 Cache
每种Cache类型都有一个此结构体:
1. 每个 CPU 的缓存 (
array[NR_CPUS])
struct array_cache *array[NR_CPUS]:这是每个 CPU 的私有缓存结构,每个 CPU 都有自己的array_cache来缓存从 slab 中分配或释放的对象。这是 per-CPU 数据结构,用于减少全局锁竞争。batchcount和limit定义了每次批量操作的数量,以及每个 CPU 缓存中可以存放的对象的数量上限。2. 全局 slab 列表 (
lists)
struct kmem_list3 lists:这个结构体用于存放和管理全局的 slab 列表。Slab 分为三类:完全分配的 slab、部分使用的 slab 和空的 slab。- Slab 分配和释放时,首先检查 per-CPU 缓存(
array_cache),如果缓存中有空闲对象,可以直接从中分配或将对象释放回缓存。如果 per-CPU 缓存满了或耗尽,则会与lists中的全局 slab 进行交互,从全局 slab 列表中分配或释放对象。3. 对象和 slab 的尺寸信息
objsize:表示每个对象的大小,Slab 分配器需要知道每个 slab 能够容纳的对象数量。num:表示每个 slab 可以容纳的对象数量,这个值根据objsize和内存页大小计算得出。slab_size:表示每个 slab 的大小,通常是以页为单位(如 4KB)。通过gfporder决定每个 slab 的页数,即以 2 的幂次表示。4. Slab 的分配和释放控制
gfporder:定义每个 slab 分配的内存页数,通常是 2 的幂次。gfporder=0表示每个 slab 占用 1 页(通常是 4KB),gfporder=1表示占用 2 页。gfpflags:定义 slab 分配时使用的内存分配标志,通常包括 GFP 高优先级(如GFP_KERNEL、GFP_DMA等),用于定义内存分配策略。spinlock:用于在多处理器系统中对全局 slab 进行同步,防止并发访问冲突。这个锁主要在lists中的 slab 分配和回收时使用。5. 颜色优化(cache colouring)
colour、colour_off、colour_next:这些字段用于实现缓存着色(cache colouring)技术,缓存着色的主要目的是为了减少缓存冲突,提高缓存命中率。它通过在每次分配 slab 时在不同的偏移位置开始分配对象,从而避免多个对象在缓存中的地址出现冲突。6. 构造和析构函数
ctor和dtor:这些是构造函数和析构函数指针,用于在分配 slab 时对对象进行初始化(构造)和在释放时执行清理(析构)。这有助于在对象分配和回收时保持一致性和清理工作。7. Slab 的分配和增长
- Slab 的增长机制(
cache_grow)是在当前缓存不够时,分配新的 slab 并将其添加到全局或 per-CPU 的 slab 列表中。kmem_cache_s中的gfporder和gfpflags控制 slab 的增长过程。- 当内存紧张时,Slab 分配器也会通过
cache_shrink机制来释放多余的 slab,这些 slab 的状态是空闲的,意味着没有分配的对象。8. 统计信息(可选)
- 如果开启了
STATS宏,kmem_cache_s还可以跟踪相关的统计信息,如活跃对象数量、分配次数、释放次数、缓存命中率等。- 这些统计信息有助于分析和优化内存分配的性能。
struct kmem_cache_s { |
关于
struct array_cache *array[NR_CPUS];,其中存放了每个cpu的缓存对象,可以不访问全局slab而直接访问缓存对象,可有效防止同步竞争。具体结构体为:
struct array_cache { |
2.2.3 slab
利用s_mem来存储obj
/* |